
Issue #5 - Developing Strategic Options Part 2, Stoicism - One cause of anger and my all-time favourite machine learning project

Hey all,
You may have noticed a change in the style of this week’s newsletter. As I mentioned last week, I was previously using Revue however they are closing down so I have now moved across to Substack.
This week we have…
Developing Strategic Options - SWOT to TOWS (part 2)
Stoicism - One cause of anger (by a guest contributor)
My all-time favourite machine learning project
MBA - Developing Strategic Options - TOWS (part 2)

Last week we introduced the SWOT analysis tool. This week we’re going to make it more meaningful.
My experience is that most strategy sessions will include something like the SWOT, but the SWOT tool only paints a picture of how things are. Instead, we are looking for the stage after that, the list of things we can actually do - our strategic options.
This week I’ll try to demonstrate this by demonstrating it using my newsletter as an example. I’m not sure it is the next example, but it is an example nonetheless.
So let’s start with a SWOT for my newsletter.

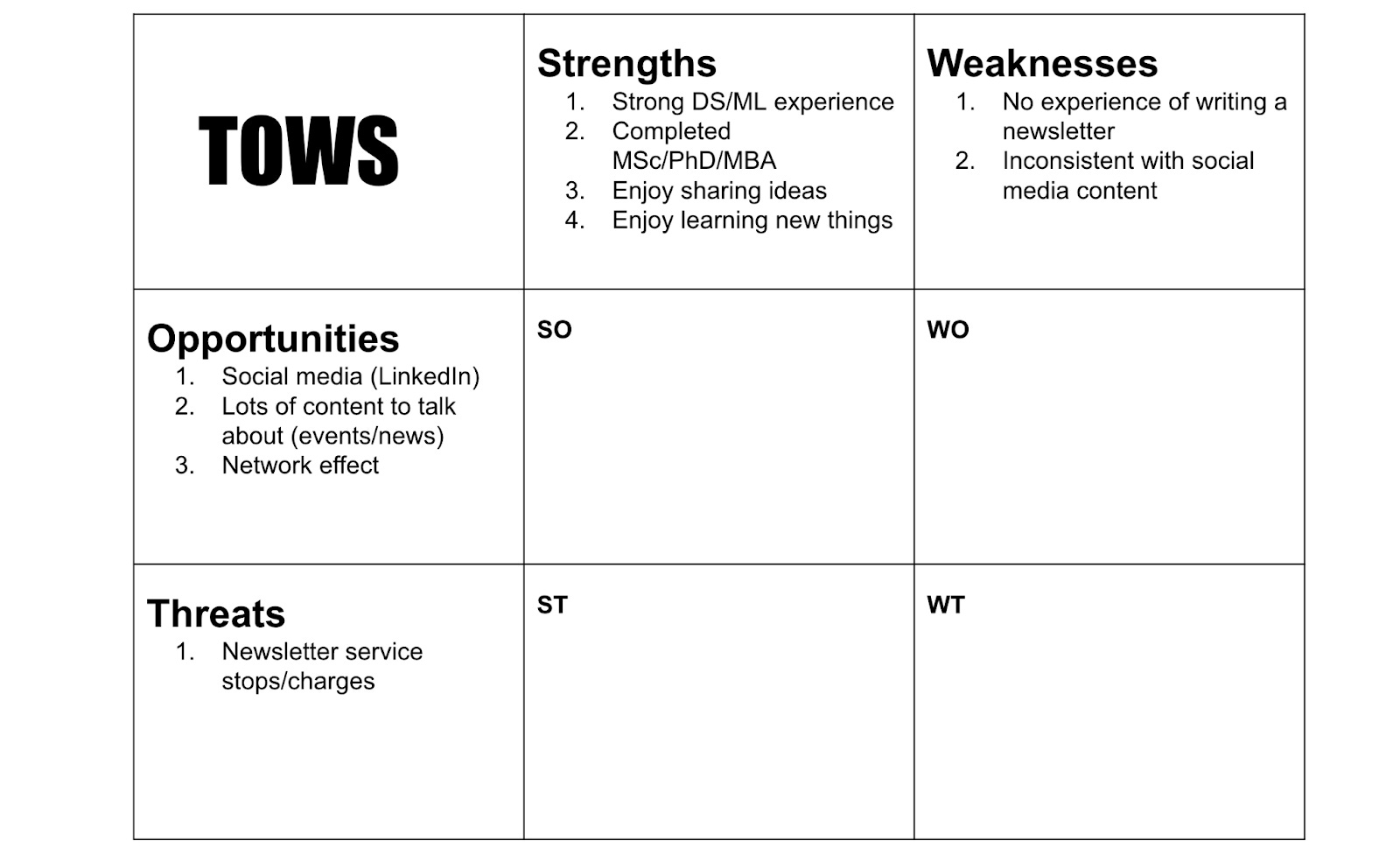
Here we can see that I have listed 4 strengths, 2 weaknesses, 3 opportunities and 1 threat. To call a few out.
Strength 1 - Strong DS/ML experience - perhaps that isn’t a strength, compared to others, there are plenty of people with lots of DS/ML experience
Strength 2 - this is unique, there are not too many people with an MBA and MSc/PhD in data science
Opportunity 1 - Social Media - calling out LinkedIn specifically - one guy I work with posts 2-3 times per week on LinkedIn, and in 3 years his posts have been viewed 100 million times - that is definitely an opportunity
Threat 1 - this actually happened
So how do we actually use this information to help us decide what our options are? First, we convert the SWOT into its new form called TOWS, and it would look like this…
Here we create 4 new boxes in the centre. The aim is to identify combinations of the Strengths, Weaknesses, Opportunities and Threats which naturally align. We are aiming to identify the actions we can take to either build upon the strengths and opportunities or to mitigate the weaknesses and threats.
A completed example can be seen below…

For my newsletter we can see five actions I should do…
SO1 - Share insights on social media that bridge the gap between the MBA and Data Science
SO2 - Stay up to date with the latest insights and draft into consumable content
ST1 - Review different newsletter service providers and develop a contingency plan
WO1 - Check online sources daily and commit to sharing 5 (minimum) social media posts per week
WT1 - Write content for multiple platforms, therefore, reducing the reliance on a single one
Using WT1 as an example. I identified the threat of a newsletter service stopping or starting to charge money (i.e. being reliant on a single platform) along with the weakness of my being inconsistent in posting social media content. Therefore an action I can do is write content for multiple platforms, thereby reducing the reliance on a single platform.
So there you go, we introduced the TOWS model and gave an example. While we applied it to my newsletter please remember it is the technique that is important.
I would also recommend you apply this to multiple scenarios, perhaps your business, your team or even yourself for career development purposes.
[Guest Post] Stoicism - Anger is caused by something as innocent as optimism

Οne of the best ideas of the Stoics was that anger is caused by something as innocent as optimism. Behind every outburst of anger, there is indeed a great hope for a world that could be better, that a partner will never say or do anything annoying, that the things we love will not break, that we will not find queues and traffic jams, that society could be completely rid of corruption. But life is not like that, so why the anger? In the Enchiridion, Epictetus asks the Romans to think about what they will find in the public baths where they go to relax: noisy bathers splashing dirty water or stealing their wallets. So, why do we get angry with such predictable things? Isn't peace of mind more important? And is it not easier to achieve by maintaining realistic expectations for life?
Stoicism is a philosophy that wants to gently disappoint us about the world and this is something useful because it has a calming effect on the psyche. The last time my wallet was stolen I thought of Epictetus – a small price you paid for the tranquillity of your soul, he told me. And if we happen to get angry on social media, let's not react immediately, let's not contribute to ugliness "Anger is temporary madness" and "The best cure for anger is delay," Seneca said. After Epictetus and Seneca, how can one be angry?
Picture - view of the Saronic Golf in Aegina, Greece. Nature always works in the service of tranquillity
My all-time favourite machine learning project - Playing Atari 2600 games with deep reinforcement learning

It would have been early 2014, I was doing my MSc in Intelligent Systems and Robotics and I was just assigned a supervisor for my final project. I wanted to do it on pathfinding in games, but my supervisor wasn’t keen and instead steered me towards a project he was working on. The project was exploring using reinforcement learning to play games.
Some details about the project. We were using deep reinforcement learning with the Arcade Learning Environment (ALE) which could play Atari 2600 games. So what is deep reinforcement learning?
Let’s split it into a couple of parts.
First, let’s look at reinforcement learning. We were using Q Learning where each state (s) had an action (a) often referred to as Q(s, a) [read more here]. Here the state was a representation of the screen and the action was a control input (left, right, up, down, fire). So for any given state, an action could be performed.
Next, let’s look at the ‘deep’ part. This was a convolutional part of a neural network. Essentially it was a way of reducing the resolution of the screen image into a smaller representation. An example is shown in the image for this post.
So pulling it all together, you’d have a raw screen image as an input into the convolutional neural network, and the image would be made smaller as it passed through the convolutional layers before hitting the neural network. At this point, we hit that Q(s, a) where each action would be given a prediction which decided which action to take.
Now that’s a super simplified version of it all, but why did I like it?
It was so new, Deepmind had only just shared their work [paper]
Using convolutional neural networks was totally new to me
The system was self-training - it did a bunch of behaviours and learned from any rewards it got
Fin.
Next week is the Christmas holidays, so I’ll probably do a shorter version of the newsletter next week.
But for now, wishing you all a great holiday season.